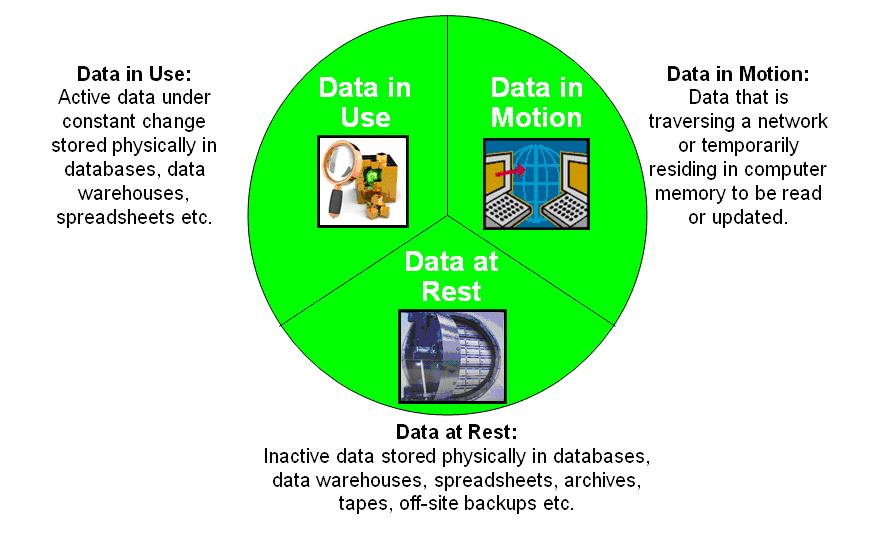

What is data at rest?
Data at rest is data that has reached a destination and is not being accessed or used.
It typically refers to stored data and excludes data that is moving across a network or is temporarily in computer memory waiting to be read or updated. Data at rest can be archival or reference files that are rarely or never changed. It can also be data that is subject to regular but not constant change.
Hackers are an ever-present threat to data at rest. To keep unauthorized people from accessing, stealing or altering this data, security measures such as encryption and hierarchical password protection are commonly used. For some types of data, laws mandate specific security measures.
Data at rest is relatively easy to secure compared with data in motion and data in use.

Examples of data at rest
There are many types of data at rest, some examples include data stored in the following ways:
- on a computer or mobile device;
- on a database server;
- on an external backup medium, such as a USB flash drive, an external hard drive or a backup storage array;
- on a storage area network array or a network-attached storage system; and
- on the servers of an offsite cloud backup service provider.
Data at rest is one of three states of data. The other two are:
- Data in motion. This data state is also called data in transit. It is data moving between systems or devices. Examples include data moving between virtual machines in cloud networks and data moving among devices on a virtual private network.
- Data in use. This state includes data that is being processed, accessed or read. For example, when a user requests access to their transaction history in a banking application, the transaction data is considered data in use.
Security concerns for data at rest
Data at rest is considered the easiest type to secure. Yet, it is still vulnerable to mistakes and malicious attacks. Those risks increase the longer data resides in storage or on a device.
Data at rest in mobile devices is at greater risk than data in other types of devices. Mobile devices are more distributed and, thus, more difficult to secure. Both factors make sensitive data stored on them more vulnerable to attacks.
For example, an employee storing sensitive company information on a mobile device could use that device on an insecure network. That puts the data at risk even if it isn’t in use. If the device is hacked, attackers could access the stored data.
Using third-party services and distributed storage methods also raises risks to data at rest. The more places data is stored and the more entities that handle it, the more at risk it is. Organizations should assess the security policies of the third parties they entrust with their data. The integrity and challenges of a cloud storage provider’s security ecosystem affect the data security of their customers. It’s particularly important to understand where the provider’s security responsibilities end and the customer’s begin.
Organizations should also understand the security and data handling regulations of the country or countries where they physically store data. For example, the European Union’s General Data Protection Regulation affects organizations that store their data in the EU and organizations that store the data on EU citizens outside of the EU.
Data breaches can be costly. Organizations could face financial and legal consequences if they become the victim of a data breach. They can also suffer reputation damage or lose customer trust.
Best practices and options for securing data at rest
Some best practices for securing data at rest include the following:
- Data classification. Organizations must know what data is stored where, how important it is and how it should be protected. Data classification involves proactively identifying and organizing data based on how sensitive it is. Organizations should assess and rank applications and data to determine which are the most critical to business processes. Data classification applications are available to help automate the process and ensure that criteria are consistently applied.
- Data encryption. Data at rest encryption prevents data from being visible in case of unauthorized access. Organizations can encrypt sensitive files before they are moved or use full-disk encryption to encrypt the entire storage medium. Users need an encryption key to read encrypted data. Encryption keys are sensitive data themselves and must be treated as such. An encryption key management service can be used to protect them.
- Data federation. Organizations use data federation to collect data from disparate sources into a single virtual database. There, the metadata is exposed, but the data is not visible. Federating data organizes it in a central location while still protecting it. Data federation software is useful in a distributed data environment, when data is stored in countries with different data protection regulations.
- Data tokenization. This approach substitutes sensitive data with non-sensitive tokens that are meaningless on their own and do not relate to the data they represent. Tokens have no exploitable value if intercepted or stolen. Tokenization is similar to encryption technologies but generally takes less computational resources.
- Hierarchical password protection. This approach lets organizations set access control for data at different sensitivity levels and assign passwords based on those levels.
Data backups are a common destination for data at rest. Learn how IT admins can protect data backups from corruption, unauthorized access and leaks